

一句話: 建 Agent Team 的核心工作是定義規格,不是寫程式。
97% Markdown:最反直覺的數據
七天後我回頭看數據,有一個數字讓我愣了一下:這個 Agent Team 在所有產出的檔案中,97% 是 Markdown。[3]
31 個 session,292 小時的互動時長,487 次我發出的訊息,3,525 次 AI 的回應,修改了 325 個檔案,新增了超過兩萬行內容,而在所有被標記的語言類型中,1242 次中有 1,150 次是 Markdown,程式碼的比例極低。
我原本以為「建一支 Agent Team」是一個工程任務,會寫很多 TypeScript 或 Python,處理 API 串接、做資料庫遷移、建通訊管線,但實際上我在做的事情是:寫 CLAUDE.md 定義每個 Agent 的身份,寫 METHODOLOGY.md 定義每個 Agent 的思考框架,寫 Skill 文件定義每個 Agent 的能力,寫 wiki 頁面累積跨 Agent 的共享知識,寫 contract 文件定義資產的品質標準,寫 state file 記錄團隊的即時狀態,真正的程式碼反而是下一個階段,跟這個 Agent Team 的核心沒有關係。
1,080,005 個 output tokens,大約等於 800 頁書的量, 而這 800 頁幾乎全是自然語言的規格和知識,不是程式碼。
| 指標 | 數據 |
|---|---|
| Sessions | 31 |
| 互動時長 | 292 小時 |
| 人類訊息 | 487 次 |
| AI 回應 | 3,525 次 |
| 修改檔案 | 325 個 |
| 新增內容 | 20,000+ 行 |
| Output tokens | 1,080,005(≈ 800 頁書) |
| Markdown 比例 | 1,150 / 1,242 = 92.6% |
這違反了一個大家很習以為常的認知:「建 AI Agent = 寫程式」,但我必須說,至少在 Agent Team 這個層級,建構的核心工作是定義規格,而不是實作功能,[2] 因為 Agent 的行為是被他的 Context 決定的[9](這正是 Context Engineering 的核心論點)[1],你改一行 CLAUDE.md 對 Agent 行為的影響,可能遠大於你寫一百行程式碼(雖然你也沒辦法預測他會怎麼解讀那一行,這也是後面幾篇會談到的坑)。
這也解釋了為什麼 HANDOFF.md 是第一個產出,為什麼架構是從需求長出來而不是預先設計好的,因為在這個範式裡,每一份文件都是一個設計決策的具象化, 我們透過寫文件來設計系統,而不是單純的「寫文件」。
兼職的建築師
還有一組數據值得一提,跟時間有關。
這七天的活動時段呈現很明顯的雙峰分布:下午 1 到 4 點,以及晚間 23 到凌晨 2 點,Agent Team 的建構全部發生在下午跟深夜,這帶出了一個不明顯但重要的特性:Agent Team 必須能承受間歇式的工作節奏。 我不是連續七天坐在電腦前不間斷地建構,而是每天花幾個小時推進,然後睡覺,隔天再接著做。每次「接著做」的時候,我面對的都是一堆不同狀態的 session,有的完成了,有的做到一半,有的等著其他 Agent 的輸出才能繼續。
而這正是 state file 和 HANDOFF 機制存在的原因,也是為什麼 GM 的設計後來演變成「artifact-based 的進度判斷」而不是「memory-based 的對話延續」:不是靠記住上一次的對話內容來判斷現在該做什麼,而是靠檔案系統上的實際產出(哪些檔案存在、哪些進度被推上了 Git、哪些狀態紀錄被更新了)來判斷目前進度。
16 次平行作業的紀錄也從側面印證了這一點,涉及 17 個 session、59 則訊息,代表我經常同時讓好幾個 Agent 在做不同的事,然後在某個時間點把他們的產出收攏回來[5],這不是設計好的工作流程,而是一個人在同時推好幾件事情時自然發展出來的習慣。
一個場景:平行處理的第一次
在所有的建構過程中,有一個場景特別值得記錄,因為它是 Agent Team 真正「像一個 Team」在運作的第一次。
那天我手上有三個從外部 repo 打包好的 Plugin,需要同時做兩件事:讓 Em 從這些 Plugin 裡萃取知識方法論存進 wiki,以及讓 C7 把這些 Plugin 登錄進資產目錄,這兩件事完全獨立,Em 關心的是「這些 Plugin 裡有什麼值得學的 pattern」,C7 關心的是「metadata 怎麼填、contract 有沒有符合」,所以我跟 Agent(當時還是我自己在扮演 GM 的角色)說「都給我,我平行處理」。
兩個 Agent 各自跑完之後,C7 的 catalog 從 0 個 Plugin 變成 3 個,Em 的 wiki 從 28 個 concepts 變成 32 個,同時新增了 1 個 source 和 1 個 entity,各自的產出都很完整。
但接下來我問了自己一個問題:Em 跟 C7 產出了什麼?怎麼跟 GM 回報? 答案是,沒有回報機制!兩個 Agent 各自完成了工作,但 GM 不知道他們做了什麼,除非我主動去讀他們的產出,Em 更新了 wiki concept,C7 登錄了新的 plugin metadata,但這兩件事之間的關聯(比如 Em 發現了一個新的 multi-phase-llm-pipeline pattern,而這個 pattern 正好被 C7 新登錄的某個 Plugin 實作了),沒有任何人在串聯。
這就是後來 Completion Reporting Protocol 被設計出來的原因,也是 GM 的核心職責之一,不只是派工,還要讓「各自獨立完成的工作」產生「加在一起的意義」,但在那個當下,這件事是我自己做的,我讀完兩邊的產出之後,手動在腦中做了交叉引用,然後把這個 insight 記錄下來,告訴下一個 session「這兩個 Agent 的產出之間有這樣的關聯」。
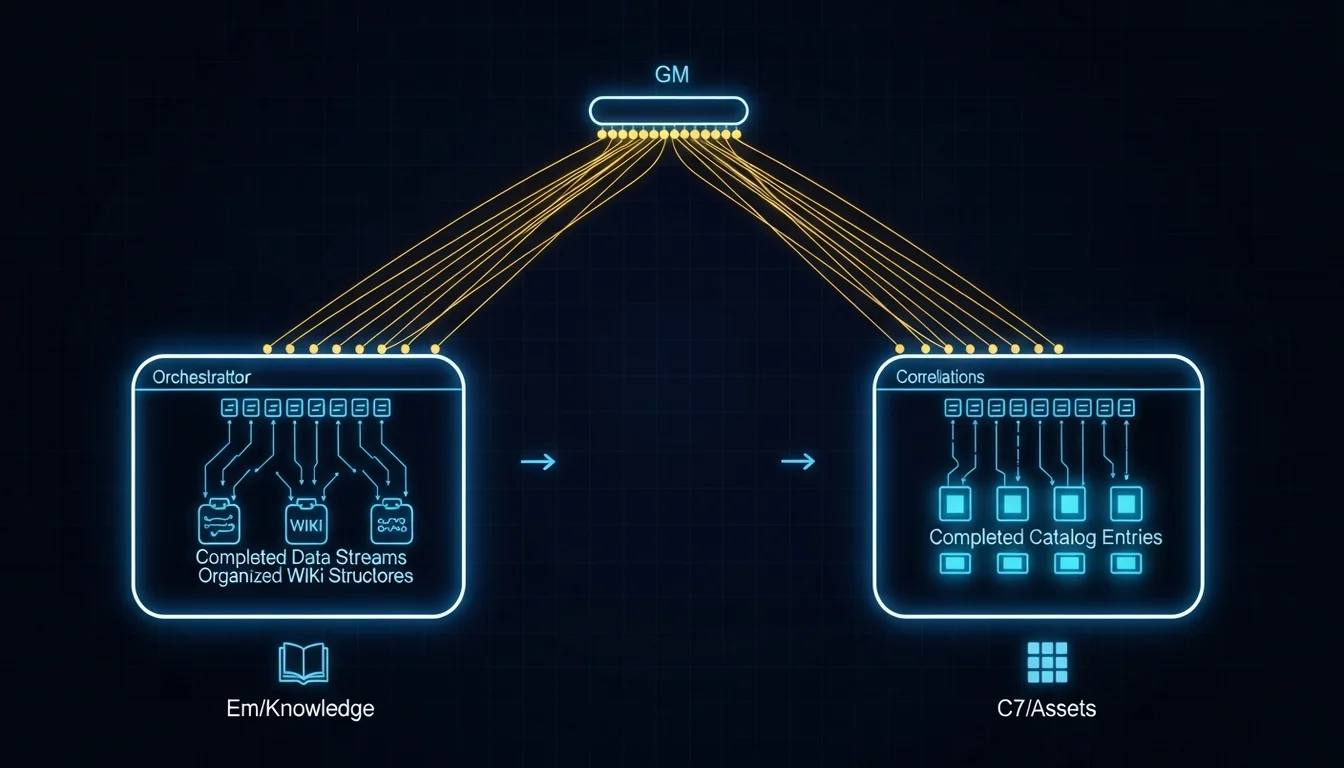
那一刻我意識到,Agent Team 的 GM 不只是一個 dispatcher,他更像是一個 sense-maker, 把散落在不同 Agent 產出中的碎片拼成一幅完整的圖。
不是自動化,是結構化
回到開頭那個凌晨兩點的場景,如果你問我「建了 Agent Team 之後,那個 Context 搬運的問題解決了嗎?」,老實說,沒有完全解決(要說完全解決那是騙人的,畢竟七天能做的有限),但問題的性質改變了。
以前我搬運 Context 是因為「沒有適當的地方可以放」,每個 session 像是一座無法通訊的孤島,Context 只能存在於對話歷史裡,Session 結束就消失,我需要從上帝視角以不同方法來留存他,現在 Context 有了結構化的存放位置:知識在 Em 的 wiki 裡,資產在 C7 的 catalog 裡,狀態在 state file 裡,決策脈絡在 HANDOFF 文件裡,我剩下通訊的機制要考慮。
以前我在不同 session 之間扮演「翻譯」的角色,把 A 的產出翻譯成 B 能理解的語言,再把 B 的回饋翻譯回 A 的脈絡。現在每個 Agent 有了自己的身份和專業語言,Em 用 wiki 的語彙思考,C7 用 catalog 的語彙思考,他們不需要我翻譯,只需要我指出「Em 的這個 concept 跟 C7 的這個 asset 有關聯」。
以前我做協調決策是靠「我記得之前好像有討論過…」這種模糊的記憶,現在我跟 Agent 討論設計問題的時候會說「先參考 Em wiki 裡面的方法論跟知識思考之後再回答我」,讓他從結構化的知識庫裡找依據,而不是從他自己的 Context 裡瞎猜。
所以 Agent Team 解決的不是「自動化」的問題,而是「結構化」的問題, 它把原本散落在我腦中和各個 session 對話歷史裡的隱含知識,變成了放在 filesystem 上、可以被任何 Agent 在任何時間點讀取的資訊。
寫在最後
七天,31 個 session,800 頁書的量。
如果要我用一句話總結這個起點,大概是這樣的:不是 Subagent 不夠用,是你累積的 Context 已經多到,每次重新建立的成本超過了維護一個持久架構的成本, 而那個臨界點到來的時候,你會知道的,因為你會發現自己花在「讓 AI 理解現況」的時間,已經比「讓 AI 做事」的時間還多。
至於這個架構建起來之後發生了什麼,每個設計決策帶來了什麼後果,踩了哪些坑,有些坑到現在還沒爬出來…這些是接下來每一篇要講的故事。
或許,建一支 Agent Team 最反直覺的地方在於,你以為你在建一個「讓 AI 幫你做更多事」的系統,但實際上你在建的是一個「讓你能把腦子裡的東西寫出來」的框架,而那些寫出來的東西,恰好也是 Agent 需要的 Context。
或許,這就是為什麼 97% 是 Markdown。
參考資料
[1] Anthropic — Effective Context Engineering for AI Agents https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[2] GitHub Blog — Spec-Driven Development: Using Markdown as a Programming Language https://github.blog/ai-and-ml/generative-ai/spec-driven-development-using-markdown-as-a-programming-language-when-building-with-ai/
[3] WSO2 — Introducing Agent-Flavored Markdown (AFM) https://wso2.com/library/blogs/introducing-agent-flavored-markdown/
[5] Addy Osmani — The Code Agent Orchestra: What Makes Multi-Agent Coding Work(multi-agent 加入 40-50% coordination overhead 的成本數據) https://addyosmani.com/blog/code-agent-orchestra/
[9] Materialize — AI Context Engines: The Next Evolution of Context Engineering https://materialize.com/blog/ai-context-engines-context-engineering-evolution/
支持這個系列
如果這系列文章對你有幫助,考慮請我喝杯咖啡
請我喝杯咖啡
